Process
命令执行
我们以以下代码为例:
1Runtime runtime = Runtime.getRuntime();
2String cmd = "ls -l";
3Process process = runtime.exec(cmd);
实际调用了下面的exec方法:
1public Process exec(String command, String[] envp, File dir) {
2 StringTokenizer st = new StringTokenizer(command);
3 String[] cmdarray = new String[st.countTokens()];
4 for (int i = 0; st.hasMoreTokens(); i++)
5 cmdarray[i] = st.nextToken();
6 return exec(cmdarray, envp, dir);
7}
第二个参数为环境变量数组,其格式为key=value,第三个参数为命令的执行路径,如果为null,那么便为当前Java进程的工作路径,即user.dir。
StringTokenizer默认以空格、换行符、制表符,换页符(\f)为分隔单位,所以这里将命令ls -l分割为了ls和-l两部分。
1public Process exec(String[] cmdarray, String[] envp, File dir) {
2 return new ProcessBuilder(cmdarray)
3 .environment(envp)
4 .directory(dir)
5 .start();
6}
其实是用ProcessBuilder实现,此类在JDK1.5时加入。
ProcessBuilder
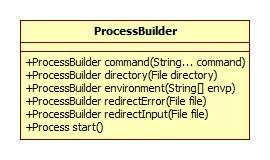
start
start方法简略版源码:
1 public Process start() throws IOException {
2 String[] cmdarray = command.toArray(new String[command.size()]);
3 cmdarray = cmdarray.clone();
4 String dir = directory == null ? null : directory.toString();
5 return ProcessImpl.start(cmdarray,
6 environment,
7 dir,
8 redirects,
9 redirectErrorStream);
10}
Redirect
redirects是一个ProcessBuilder内部的Redirect数组,Redirect为ProcessBuilder的嵌套类,定义了系统的进程的输入或输出:
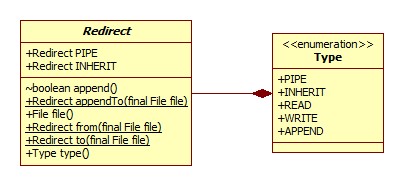
且redirects数组的大小必定为3,分别代表输入、输出和错误,此数组是lazy-init的,只有当调用其redirects()方法获取整个数组或要设置重定向时才会进行初始化,redirects()源码:
1private Redirect[] redirects() {
2 if (redirects == null)
3 redirects = new Redirect[] {Redirect.PIPE, Redirect.PIPE, Redirect.PIPE};
4 return redirects;
5}
可以看到,默认都是管道类型,这其实很容易理解,每个命令的执行都会导致一个系统进程的创建,我们从进程获得输出,输入必定要通过管道的方式。
重定向
其实共有三组方法:
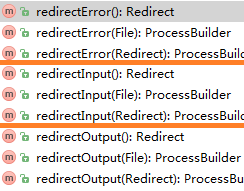
没有参数的表示获取。
获取
我们以redirectError为例:
1public Redirect redirectError() {
2 return (redirects == null) ? Redirect.PIPE : redirects[2];
3}
设置
以redirectInput为例:
1public ProcessBuilder redirectInput(File file) {
2 //对redirects数组赋值
3 return redirectInput(Redirect.from(file));
4}
from方法其实是对File的包装:
1public static Redirect from(final File file) {
2 return new Redirect() {
3 public Type type() { return Type.READ; }
4 public File file() { return file; }
5 public String toString() {
6 return "redirect to read from file \"" + file + "\"";
7 }
8 };
9}
输出整合
下面两个方法分别对redirectErrorStream属性进行读取和设置:

如果被设置为true,那么错误输出将会被merge到标准输出。
继承
即Redirect.Type.INHERIT类型。那什么是继承呢?其实就是将启动的进程的输入或输出或错误输出设置为当前Java虚拟机的输入、输出与错误输出。
inheritIO方法源码:
1public ProcessBuilder inheritIO() {
2 Arrays.fill(redirects(), Redirect.INHERIT);
3 return this;
4}
其实相当于这样:
1pb.redirectInput(Redirect.INHERIT).redirectOutput(Redirect.INHERIT).redirectError(Redirect.INHERIT);
Process
代表系统的一个进程。
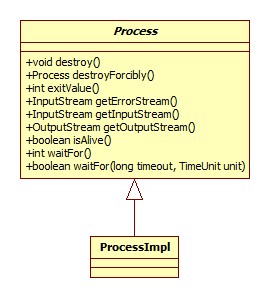
start
ProcessImpl在不同的系统上有不同的实现,我们以Linux为准,所做的是将命令、参数以及环境转为byte数组,并初始化文件描述符数组,初始化的逻辑如下:
1int[] std_fds;
2if (redirects == null) {
3 std_fds = new int[] { -1, -1, -1 };
4} else {
5 std_fds = new int[3];
6 if (redirects[0] == Redirect.PIPE)
7 std_fds[0] = -1;
8 else if (redirects[0] == Redirect.INHERIT)
9 //在nio部分提到过,在Unix下0为标准输入,1为标准输出,2为错误输出
10 std_fds[0] = 0;
11 else {
12 f0 = new FileInputStream(redirects[0].file());
13 std_fds[0] = fdAccess.get(f0.getFD());
14 }
15}
最后构造了一个UNIXProcess对象,UNIXProcess构造器源码:
1UNIXProcess(final byte[] prog,
2 final byte[] argBlock, final int argc,
3 final byte[] envBlock, final int envc,
4 final byte[] dir,
5 final int[] fds,
6 final boolean redirectErrorStream) {
7 pid = forkAndExec(launchMechanism.value,
8 helperpath,
9 prog,
10 argBlock, argc,
11 envBlock, envc,
12 dir,
13 fds,
14 redirectErrorStream);
15 doPrivileged(new PrivilegedExceptionAction<Void>() {
16 public Void run() throws IOException {
17 initStreams(fds);
18 return null;
19 }});
20}
运行模式
枚举LaunchMechanism的定义为:
1private static enum LaunchMechanism {
2 FORK(1),
3 VFORK(3);
4 private int value;
5 LaunchMechanism(int x) {value = x;}
6};
fork和vfork其实是Linux中两种子进程的启动方式,关于它们的区别可参考:
字段launchMechanism在静态代码块中初始化:
1static {
2 launchMechanism = AccessController.doPrivileged(
3 new PrivilegedAction<LaunchMechanism>() {
4 public LaunchMechanism run() {
5 String s = System.getProperty(
6 "jdk.lang.Process.launchMechanism", "vfork");
7 return LaunchMechanism.valueOf(s.toUpperCase());
8 }
9 });
10}
在Linux上默认使用vfork,即无需拷贝拷贝父进程的数据,子进程执行时父进程必须等待。
forkAndExec方法为native实现,由vfork系统调用实现。
流初始化
共可以获得三种流,方法名如下图:
其中errorStream对应子进程的错误输出流,inputStream对应子进程的标准输出流(未重定向的前提下),outputStream对应子进程的标准输入流(未重定向的前提下)。
UNIXProcess.initStreams:
1void initStreams(int[] fds) throws IOException {
2 stdin = (fds[0] == -1) ?
3 ProcessBuilder.NullOutputStream.INSTANCE :
4 new ProcessPipeOutputStream(fds[0]);
5 stdout = (fds[1] == -1) ?
6 ProcessBuilder.NullInputStream.INSTANCE :
7 new ProcessPipeInputStream(fds[1]);
8 stderr = (fds[2] == -1) ?
9 ProcessBuilder.NullInputStream.INSTANCE :
10 new ProcessPipeInputStream(fds[2]);
11 processReaperExecutor.execute(new Runnable() {
12 public void run() {
13 int exitcode = waitForProcessExit(pid);
14 UNIXProcess.this.processExited(exitcode);
15 }});
16}
上面提到的三个方法实际上就是返回这里的三个字段中的一个。注意forkAndExec方法会改变fds的值,在这里-1表示在ProcessBuilder中我们指定了重定向,比如我们将子进程的输出指定到一个文件,那么这里的stdin就是NullOutputStream。ProcessBuilder.NullOutputStream:
1static class NullOutputStream extends OutputStream {
2 static final NullOutputStream INSTANCE = new NullOutputStream();
3 private NullOutputStream() {}
4 public void write(int b) throws IOException {
5 throw new IOException("Stream closed");
6 }
7}
等待结束
即initStreams方法中的:
1processReaperExecutor.execute(new Runnable() {
2 public void run() {
3 int exitcode = waitForProcessExit(pid);
4 UNIXProcess.this.processExited(exitcode);
5 }
6});
processReaperExecutor为Java线程池,所以这里使用了单独的线程来进行等待。waitForProcessExit为native实现,通过Linux waitpid及其相关系统调用实现,可参考Linux man或:
UNIXProcess.processExited:
1void processExited(int exitcode) {
2 synchronized (this) {
3 this.exitcode = exitcode;
4 hasExited = true;
5 //唤醒所有正在等待的线程
6 notifyAll();
7 }
8 if (stdout instanceof ProcessPipeInputStream)
9 ((ProcessPipeInputStream) stdout).processExited();
10 if (stderr instanceof ProcessPipeInputStream)
11 ((ProcessPipeInputStream) stderr).processExited();
12 if (stdin instanceof ProcessPipeOutputStream)
13 ((ProcessPipeOutputStream) stdin).processExited();
14}
我们来看一下processExited方法做了什么,以ProcessPipeInputStream为例:
1synchronized void processExited() {
2 try {
3 InputStream in = this.in;
4 if (in != null) {
5 InputStream stragglers = drainInputStream(in);
6 in.close();
7 this.in = stragglers;
8 }
9 } catch (IOException ignored) { }
10}
drainInputStream方法的作用检测输入流(即子进程的输出)中是否还有数据未被读取,如果有将其读取出来并包装为ByteArrayInputStream返回,否则 返回NullInputStream。
为什么会阻塞
回想之前在实际项目中遇到的问题: 如果我们不读取输入流(子进程的输出)的数据,那么waitFor方法将一直不能返回。
原因就在于在没有重定向的情况下进程和子进程之间使用管道进行通信,而管道的大小也是有一定的限制的,写满之后write调用便会阻塞。
管道的大小可通过命令ulimit -a查看,如下图:
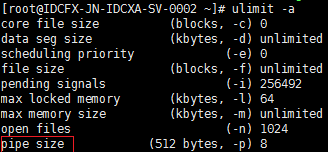
512字节。
waitFor
UNIXProcess.waitFor:
1public synchronized int waitFor() {
2 while (!hasExited) {
3 wait();
4 }
5 return exitcode;
6}
wait就是Object的wait方法,结合Process-start-等待结束即可 。
destroy
destroy()和destroyForcibly()方法其实都是对私有方法destroy(boolean force)的调用,只不过前者参数为false,后者为 true:
1private void destroy(boolean force) {
2 synchronized (this) {
3 if (!hasExited)
4 destroyProcess(pid, force);
5 }
6 try { stdin.close(); } catch (IOException ignored) {}
7 try { stdout.close(); } catch (IOException ignored) {}
8 try { stderr.close(); } catch (IOException ignored) {}
9}
正如jdk的注释中所说,这里其实有潜在的竞争条件,即在!hasExited检查通过之后子进程执行完毕,同时有可能Linux会对进程号进行回收,从而导致进程误杀的情况,只不过概率相当小。
destroyProcess为native方法:
1JNIEXPORT void JNICALL
2Java_java_lang_UNIXProcess_destroyProcess(JNIEnv *env,
3 jobject junk,
4 jint pid,
5 jboolean force) {
6 int sig = (force == JNI_TRUE) ? SIGKILL : SIGTERM;
7 kill(pid, sig);
8}
kill即Linux系统调用。
exitValue
获取返回值:
1public synchronized int exitValue() {
2 if (!hasExited) {
3 throw new IllegalThreadStateException("process hasn't exited");
4 }
5 return exitcode;
6}
isAlive
jdk1.8加入的方法:
1@Override
2public synchronized boolean isAlive() {
3 return !hasExited;
4}