IO
File
类图:
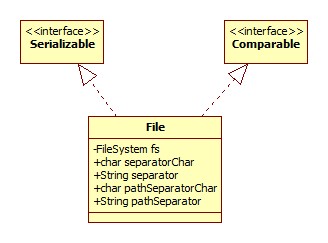
其实观察File里面多数方法的实现,其实是通过委托给属性fs完成的。
FileSystem
在 File中的初始化代码:
1private static final FileSystem fs = DefaultFileSystem.getFileSystem();
在Windows下的类图:

那DefaultFileSystem又是个什么东西呢?这东西是从JDK8加入的 ,全部的源码如下:
1class DefaultFileSystem {
2 public static FileSystem getFileSystem() {
3 return new WinNTFileSystem();
4 }
5}
可以想象,在Linux上一定是不同的实现。
文件创建
我们来看看创建文件时到底发生了什么,以代码:
1File file = new File("test");
2System.out.println(file.getAbsolutePath());
File构造器:
1public File(String pathname) {
2 this.path = fs.normalize(pathname);
3 this.prefixLength = fs.prefixLength(this.path);
4}
normalize
这一步是将文件分隔符、路径分隔符转换成系统特定的,比如对于windows平台,就将/转为\。转换的过程不再赘述,来看一下系统特定的分隔符是从哪来的,WinNTFileSystem构造器:
1public WinNTFileSystem() {
2 slash = AccessController.doPrivileged(new GetPropertyAction("file.separator")).charAt(0);
3 semicolon = AccessController.doPrivileged(new GetPropertyAction("path.separator")).charAt(0);
4 altSlash = (this.slash == '\\') ? '/' : '\\';
5}
其实就是System.getProperty。
绝对路径获取
File.getAbsolutePath:
1public String getAbsolutePath() {
2 return fs.resolve(this);
3}
resolve遵从下面的逻辑:
- 如果给定的路径已经是绝对路径,那么直接返回。
- 获取系统变量user.dir,将文件指向此目录,而user.dir默认便是java程序执行的路径。
到这里并未涉及到任何系统层面的API操作。
文件/目录判断
其实是一样的套路:
1public boolean isDirectory() {
2 return ((fs.getBooleanAttributes(this) & FileSystem.BA_DIRECTORY != 0);
3}
4
5public boolean isFile() {
6 return ((fs.getBooleanAttributes(this) & FileSystem.BA_REGULAR) != 0);
7}
getBooleanAttributes为native实现。位于WinNTFileSystem_md.c,核心源码:
1JNIEXPORT jint JNICALL
2Java_java_io_WinNTFileSystem_getBooleanAttributes(JNIEnv *env, jobject this, jobject file) {
3 jint rv = 0;
4 jint pathlen;
5 WCHAR *pathbuf = fileToNTPath(env, file, ids.path);
6 DWORD a = getFinalAttributes(pathbuf);
7 rv = (java_io_FileSystem_BA_EXISTS
8 | ((a & FILE_ATTRIBUTE_DIRECTORY)
9 ? java_io_FileSystem_BA_DIRECTORY : java_io_FileSystem_BA_REGULAR)
10 | ((a & FILE_ATTRIBUTE_HIDDEN) ? java_io_FileSystem_BA_HIDDEN : 0));
11 return rv;
12}
getFinalAttributes即Windows API,其实此函数可以返回更多的属性信息,而源码中的一系列与或操作将很多属性屏蔽了,只保留以下:
- 是否存在
- 文件还是目录
- 是否是隐藏文件/目录
FileSystem.BA_REGULAR等属性定义在抽象类FileSystem中:
1@Native public static final int ACCESS_READ = 0x04;
2@Native public static final int ACCESS_WRITE = 0x02;
3@Native public static final int ACCESS_EXECUTE = 0x01;
即:每一个属性用int中的一位来存储。
可读/可写/可执行
File.canRead:
1public boolean canRead() {
2 return fs.checkAccess(this, FileSystem.ACCESS_READ);
3}
写也是一样的。checkAccess为native实现:
1JNIEXPORT jboolean
2JNICALL Java_java_io_WinNTFileSystem_checkAccess(JNIEnv *env, jobject this, jobject file, jint access) {
3 DWORD attr;
4 WCHAR *pathbuf = fileToNTPath(env, file, ids.path);
5 // Windows函数
6 attr = GetFileAttributesW(pathbuf);
7 attr = getFinalAttributesIfReparsePoint(pathbuf, attr);
8 switch (access) {
9 case java_io_FileSystem_ACCESS_READ:
10 case java_io_FileSystem_ACCESS_EXECUTE:
11 return JNI_TRUE;
12 case java_io_FileSystem_ACCESS_WRITE:
13 /* Read-only attribute ignored on directories */
14 if ((attr & FILE_ATTRIBUTE_DIRECTORY) ||
15 (attr & FILE_ATTRIBUTE_READONLY) == 0)
16 return JNI_TRUE;
17 else
18 return JNI_FALSE;
19 default:
20 assert(0);
21 return JNI_FALSE;
22 }
23}
从这里可以看出,对于读和执行权限,只要路径存在且合法,直接返回true,而可写的条件是: 路径是一个目录或非只读文件。
list
此方法用以列出一个目录下的所有子文件(夹)。使用WinNTFileSystem的同名native方法实现,源码较长,在此不再贴出,实现的原理便是利用Windows的FindFirstFileW和FindNextFileW,两个函数的W结尾表示Unicode编码,参考:
使用FindFirstFile,FindNextFile遍历一个文件夹
mkdir(s)
mkdir实现:
1public boolean mkdir() {
2 return fs.createDirectory(this);
3}
而mkdirs使用mkdir实现:
1public boolean mkdirs() {
2 File parent = getCanonicalFile().getParentFile();
3 return (parent != null && (parent.mkdirs() || parent.exists()) &&
4 canonFile.mkdir());
5}
createDirectory为native实现,对应Windows CreateDirectoryW函数。
文件删除
native由removeFileOrDirectory函数完成,源码:
1static int removeFileOrDirectory(const jchar *path) {
2 /* Returns 0 on success */
3 DWORD a;
4 SetFileAttributesW(path, FILE_ATTRIBUTE_NORMAL);
5 a = GetFileAttributesW(path);
6 if (a == INVALID_FILE_ATTRIBUTES) {
7 return 1;
8 } else if (a & FILE_ATTRIBUTE_DIRECTORY) {
9 //删除目录
10 return !RemoveDirectoryW(path);
11 } else {
12 return !DeleteFileW(path);
13 }
14}
移动/重命名
由Windows函数_wrename实现。
length
用以获取文件的大小,Linux实现由stat函数完成。
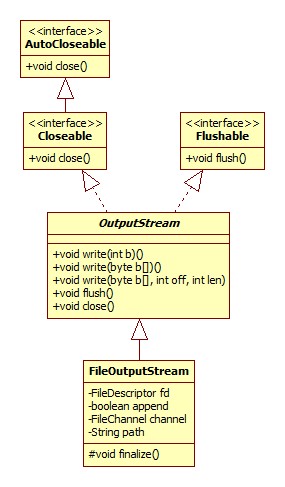
FileOutputStream
类图:
构造器
以File参数构造器为例:
1public FileOutputStream(File file, boolean append) {
2 String name = (file != null ? file.getPath() : null);
3 this.fd = new FileDescriptor();
4 fd.attach(this);
5 this.append = append;
6 this.path = name;
7 open(name, append);
8}
第二个参数为是否追加写,默认false。
open调用了native实现的open0:
1JNIEXPORT void JNICALL Java_java_io_FileOutputStream_open0(JNIEnv *env, jobject this, jstring path, jboolean append) {
2 fileOpen(env, this, path, fos_fd,
3 O_WRONLY | O_CREAT | (append ? O_APPEND : O_TRUNC));
4}
fileOpen最终调用Windows API CreateFileW函数,我们在这里只关注一下参数:
1O_WRONLY | O_CREAT | (append ? O_APPEND : O_TRUNC)
O_WRONLY表示写文件,O_CREAT为创建文件,O_TRUNC 表示若文件存在,则长度被截为0,属性不变,参考:
写文件
实际上,所有的写操作都是通过此方法实现的:
1private native void writeBytes(byte b[], int off, int len, boolean append);
最终的写入由Windows函数WriteFile完成,io_util_md.c,writeInternal函数部分源码:
1static jint writeInternal(FD fd, const void *buf, jint len, jboolean append) {
2 result = WriteFile(h, /* File handle to write */
3 buf, /* pointers to the buffers */
4 len, /* number of bytes to write */
5 &written, /* receives number of bytes written */
6 lpOv); /* overlapped struct */
7 return (jint)written;
8}
通道获取
隔壁 FileChannel。
关闭
FileOutputStream.close:
1public void close() throws IOException {
2 //设置状态
3 synchronized (closeLock) {
4 if (closed) {
5 return;
6 }
7 closed = true;
8 }
9 //关闭通道
10 if (channel != null) {
11 channel.close();
12 }
13 fd.closeAll(new Closeable() {
14 public void close() throws IOException {
15 close0();
16 }
17 });
18}
close0为native实现,关闭其对应的文件句柄。
RandomAccessFile
老规矩,类图:
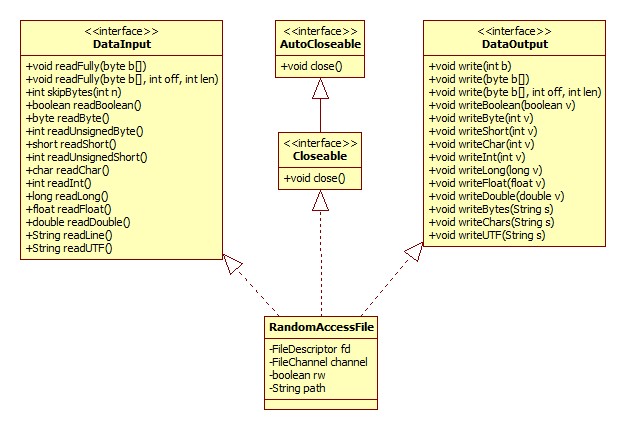
可见,这货与File, 输入输出流半毛钱的关系都没有。
模式
支持的读写模式整理如下表:
| Mode | 意义 |
|---|---|
| r | 只读 |
| rw | 读写 |
| rws | 任何对文件内容或元信息的写会被立即同步刷新至磁盘 |
| rwd | 对文件内容的写会被立即同步刷新至磁盘 |
可以看出,rws和rwd两个模式的作用和FileChannel的force方法是一样的。
构造器
简略版源码:
1public RandomAccessFile(File file, String mode) {
2 String name = (file != null ? file.getPath() : null);
3 int imode = -1;
4 fd = new FileDescriptor();
5 fd.attach(this);
6 path = name;
7 open(name, imode);
8}
open方法调用了native方法open0,此方法的实现位于src\share\native\java\io\RandomAccessFile.c:
1JNIEXPORT void JNICALL
2Java_java_io_RandomAccessFile_open0(JNIEnv *env,
3 jobject this, jstring path, jint mode) {
4 int flags = 0;
5 if (mode & java_io_RandomAccessFile_O_RDONLY)
6 flags = O_RDONLY;
7 else if (mode & java_io_RandomAccessFile_O_RDWR) {
8 flags = O_RDWR | O_CREAT;
9 if (mode & java_io_RandomAccessFile_O_SYNC)
10 flags |= O_SYNC;
11 else if (mode & java_io_RandomAccessFile_O_DSYNC)
12 flags |= O_DSYNC;
13 }
14 fileOpen(env, this, path, raf_fd, flags);
15}
结合FileOutputStream的open方法便可以发现,两者的open操作其实使用了相同的系统级实现,只不过RandomAccessFile支持更多的参数。
seek
seek允许我们自己设定当前文件的指针(偏移)。注意,系统允许设置的偏移大于文件的真实长度,但这并不改变文件的大小,只有当在新的偏移写入数据之后才会改变。
由native方法seek0调用Windows函数SetFilePointerEx实现,与之比对,FileChannel的position方法采用的是SetFilePointer函数,两者的区别是SetFilePointer将新的文件指针存放在两个long中,而SetFilePointerEX只需要一个long,至于两者为什么要采用不同的实现,不得而知。
skipBytes
用seek方法实现。
length
获取文件的大小,不同于File的length方法,此处使用seek来实现,RandomAccessFile.c相关源码(简略):
1JNIEXPORT jlong JNICALL
2Java_java_io_RandomAccessFile_length(JNIEnv *env, jobject this) {
3 FD fd;
4 jlong cur = jlong_zero;
5 jlong end = jlong_zero;
6 fd = GET_FD(this, raf_fd);
7 end = IO_Lseek(fd, 0L, SEEK_END);
8 return end;
9}
IO_Lseek对应linux上的lseek,windows上的SetFilePointer,关于为什么可以利用seek取得文件大小,参考:
setLength
此方法可以实现文件裁剪的效果,和FileChannel的truncate方法效果相同。native实现:
1JNIEXPORT void JNICALL
2Java_java_io_RandomAccessFile_setLength(JNIEnv *env, jobject this, jlong newLength) {
3 FD fd;
4 jlong cur;
5 fd = GET_FD(this, raf_fd);
6 if ((cur = IO_Lseek(fd, 0L, SEEK_CUR)) == -1) goto fail;
7 //here
8 if (IO_SetLength(fd, newLength) == -1) goto fail;
9 //重设指针
10 if (cur > newLength) {
11 if (IO_Lseek(fd, 0L, SEEK_END) == -1) goto fail;
12 } else {
13 if (IO_Lseek(fd, cur, SEEK_SET) == -1) goto fail;
14 }
15 return;
16}
IO_SetLength在Windows上的真正函数是SetFilePointer,这和FileChannel的truncate是一样的,在Linux上是ftruncate函数。
读方法
虽然RandomAccessFile和InputStream在继承上没有关系,但很多API是一样的。
读取一个字节
方法声明:
1private native int read0();
注意返回值是int,即范围为0-255,。如果我们将byte值-1写入到文件,再读出来就成了255,如要转为-1强转为byte就行了。
底层对应Windows的ReadFile,Linux的read函数。
readFully
1public final void readFully(byte b[]) throws IOException {
2 readFully(b, 0, b.length);
3}
顾名思义,此方法会在所有要求的字节读完之前阻塞,其实就是替我们做了循环判断的过程:
1 public final void readFully(byte b[], int off, int len) {
2 int n = 0;
3 do {
4 int count = this.read(b, off + n, len - n);
5 if (count < 0)
6 throw new EOFException();
7 n += count;
8 } while (n < len);
9}
"语法糖"读
指各种readInt,readChar等方法,其实就是读指定的字节然后给你拼起来。
浮点数读取/写入
我们以float为例:
1public final void writeFloat(float v) {
2 writeInt(Float.floatToIntBits(v));
3}
4public final float readFloat() throws IOException {
5 return Float.intBitsToFloat(readInt());
6}
从根本上来说,写入/读取到的只不过是一组二进制数字,关键在于我们如何解读它,所以写入/读取浮点数的关键在于如何进行浮点数和int值得转换(两者的二进制形式是一样的),上面的两个native Float方法巧妙地利用了C语言的共用体实现这一转换:
1JNIEXPORT jint JNICALL
2Java_java_lang_Float_floatToRawIntBits(JNIEnv *env, jclass unused, jfloat v) {
3 union {
4 int i;
5 float f;
6 } u;
7 u.f = (float)v;
8 return (jint)u.i;
9}
readLine
源码:
1public final String readLine() throws IOException {
2 StringBuffer input = new StringBuffer();
3 int c = -1;
4 boolean eol = false;
5 while (!eol) {
6 switch (c = read()) {
7 case -1:
8 case '\n':
9 eol = true;
10 break;
11 case '\r':
12 eol = true;
13 long cur = getFilePointer();
14 if ((read()) != '\n') {
15 seek(cur);
16 }
17 break;
18 default:
19 input.append((char)c);
20 break;
21 }
22 }
23 if ((c == -1) && (input.length() == 0)) {
24 return null;
25 }
26 return input.toString();
27}
可以看出,方法将byte转为了char,但是这样有一个问题,char是由byte转换而来,所以这里只支持ASCII字符,如果真的想要读一行不应使用此方法,而应该使用字符流。
readUnsignedByte
不是很理解这个方法的用意,源码:
1public final int readUnsignedByte() throws IOException {
2 int ch = this.read();
3 if (ch < 0)
4 throw new EOFException();
5 return ch;
6}
奇怪的地方在于这里还是只读了一个字节,之后转为int,ch怎么可能是负值?这样的话和read方法又有什么区别?
readUTF
应和writeUTF配合食用。writeUTF用于写入一个UTF-8编码的字符串,注意前两个字节代表后面有多少个字节(字符串)。所以一个10字节的字符串需要12字节存储。
感觉此方法应该是用在字符串、int等多种类型混合存储的场景下。
过滤流
或者说是包装流,类图(只列出常用的):
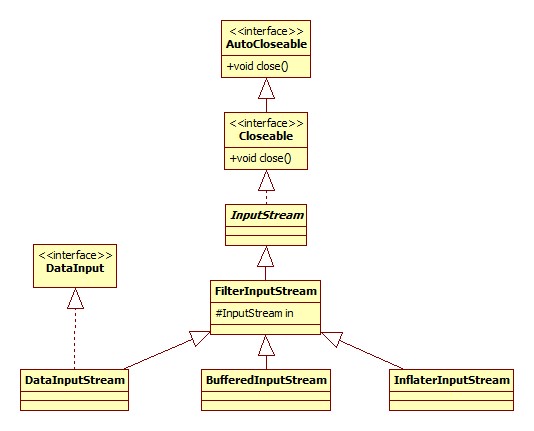
DataInputStream与RandomAccessFile的API基本一致(实现了同一个接口),InflaterInputStream用于zip压缩包的读取。
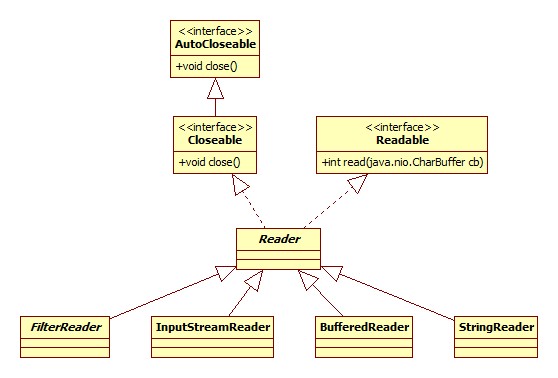
字符流
"字符"是一个文化上的概念,字符流基于字节流,只不过是按照特定的编码规则进行解码罢了。我们以Reader为例,看一下其类图即可: