FileChannel
我们以FileOutputStream的getChannel为例:
1public FileChannel getChannel() {
2 synchronized (this) {
3 if (channel == null) {
4 channel = FileChannelImpl.open(fd, path, false, true, append, this);
5 }
6 return channel;
7 }
8}
FileChannel类图:
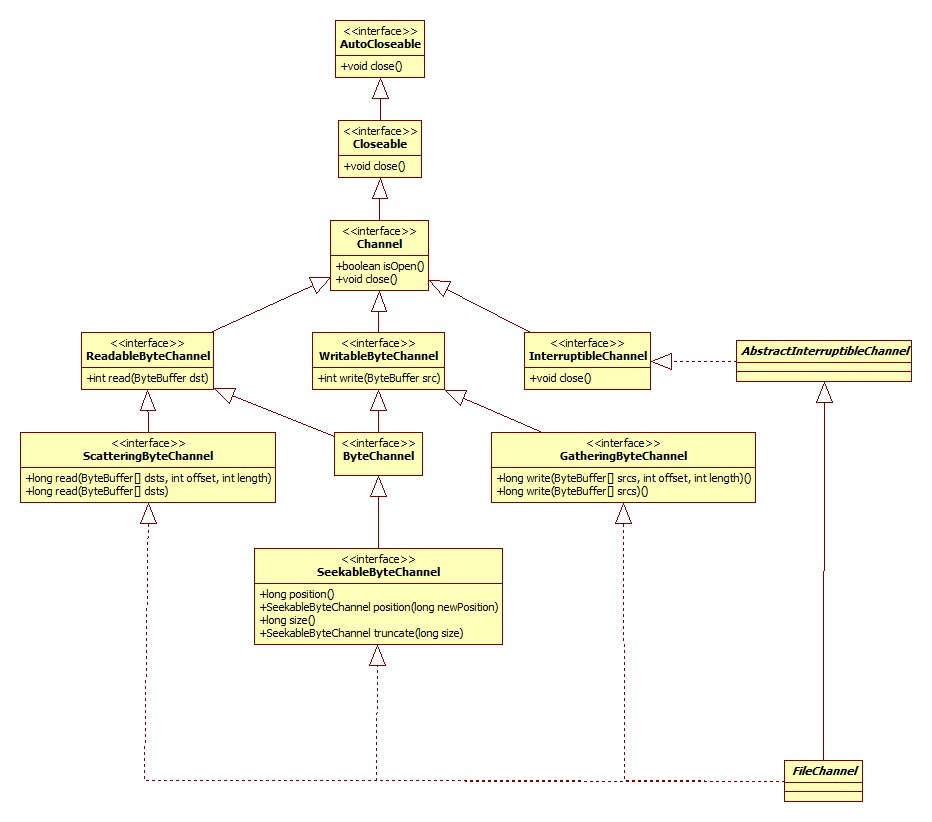
有几点值得注意:
- InputStream和OutputStream不是线程安全的,而通道(Channel)是线程安全的。
- Channel根据注释的解释,是一组IO操作的联结。
- GatheringByteChannel,顾名思义就是将一组ByteBuffer的数据收集/组合起来,所以它继承自WritableByteChannel。
- ScatteringByteChannel,即将一个通道的数据分散到多个ByteBuffer之中。
其实FileChannelImpl便是FileChannel的子类,位于包sun.nio.ch中,其源码可以从openjdk的jdk\src\share\classes\sun\nio\ch目录找到,open方法源码:
1public static FileChannel open(FileDescriptor fd, String path, boolean readable, boolean writable,
2 boolean append, Object parent) {
3 return new FileChannelImpl(fd, path, readable, writable, append, parent);
4}
可以看出,getChannel的原理就是构造了一个FileChannelImpl对象,此对象中保存有对应的流的是否可读、追加、文件描述符等属性。
从这里也可以看出,从输出流获取的通道由于readable被设为false,所以这个通道也就变成了不可读的。
写
FileChannelImpl.write简略版源码:
1public int write(ByteBuffer src) throws IOException {
2 ensureOpen();
3 synchronized (positionLock) {
4 int n = 0;
5 int ti = -1;
6 try {
7 begin();
8 ti = threads.add();
9 if (!isOpen())
10 return 0;
11 do {
12 n = IOUtil.write(fd, src, -1, nd);
13 } while ((n == IOStatus.INTERRUPTED) && isOpen());
14 return IOStatus.normalize(n);
15 } finally {
16 threads.remove(ti);
17 end(n > 0);
18 assert IOStatus.check(n);
19 }
20 }
21}
实际上从这里我们可以看出通道的可中断是怎样实现的(IO流并不可以被中断)。begin方法在父类AbstractInterruptibleChannel中实现:
1protected final void begin() {
2 if (interruptor == null) {
3 interruptor = new Interruptible() {
4 public void interrupt(Thread target) {
5 synchronized (closeLock) {
6 if (!open)
7 return;
8 open = false;
9 interrupted = target;
10 try {
11 AbstractInterruptibleChannel.this.implCloseChannel();
12 } catch (IOException x) { }
13 }
14 }};
15 }
16 blockedOn(interruptor);
17 Thread me = Thread.currentThread();
18 if (me.isInterrupted())
19 interruptor.interrupt(me);
20}
blockedOn实际上调用的是Thread的blockedOn方法:
1void blockedOn(Interruptible b) {
2 synchronized (blockerLock) {
3 blocker = b;
4 }
5}
当所在线程被中断时,blocker对象的interrupt方法将会被调用,结合上面begin方法的实现,即当发生中断时,blocker将会关闭通道,这样也就退出了阻塞。Interruptible接口定义在sun.nio.ch中,从Thread的blocker对象的注释中可以看出,此对象是专门为实现可中断的IO而设置的。
IOUtil.write的调用全部发生在sun包内,我们忽略复杂的调用关系,看一下本质: FileDispatcherImpl.c的Java_sun_nio_ch_FileDispatcherImpl_write0方法实现(简略版):
1JNIEXPORT jint JNICALL
2Java_sun_nio_ch_FileDispatcherImpl_write0(JNIEnv *env, jclass clazz, jobject fdo,
3 jlong address, jint len, jboolean append) {
4 result = WriteFile(h, /* File handle to write */
5 (LPCVOID)address, /* pointers to the buffers */
6 len, /* number of bytes to write */
7 &written, /* receives number of bytes written */
8 lpOv); /* overlapped struct */
9 return convertReturnVal(env, (jint)written, JNI_FALSE);
10}
所以,通过FileOutputStream还是FileChannel进行数据的写入,在系统层面都是一样的。
但是要注意,不同于OutputStream的write方法,这里的返回值是int。也就是说,通道的write方法并不保证一定将我们给定的数据一次性写出,正确的写姿势应该是这样的:
1while (buf.hasRemaining()) {
2 channel.write(buf);
3}
那么问题来了,既然通道和OutputStream是使用的同一个系统级API,那么后者是怎么实现的?
玄机在于jdk\src\share\native\java\io\io_util.c的writeBytes方法其实已经帮我们实现了循环过程,关键源码:
1while (len > 0) {
2 fd = GET_FD(this, fid);
3 if (fd == -1) {
4 JNU_ThrowIOException(env, "Stream Closed");
5 break;
6 }
7 if (append == JNI_TRUE) {
8 n = IO_Append(fd, buf+off, len);
9 } else {
10 n = IO_Write(fd, buf+off, len);
11 }
12 if (n == -1) {
13 JNU_ThrowIOExceptionWithLastError(env, "Write error");
14 break;
15 }
16 off += n;
17 len -= n;
18}
读
IOUtil.read源码:
1static int read(FileDescriptor fd, ByteBuffer dst, long position, NativeDispatcher nd) {
2 if (dst instanceof DirectBuffer)
3 return readIntoNativeBuffer(fd, dst, position, nd);
4 // Substitute a native buffer
5 ByteBuffer bb = Util.getTemporaryDirectBuffer(dst.remaining());
6 try {
7 int n = readIntoNativeBuffer(fd, bb, position, nd);
8 bb.flip();
9 if (n > 0)
10 dst.put(bb);
11 return n;
12 } finally {
13 Util.offerFirstTemporaryDirectBuffer(bb);
14 }
15}
从这里可以看到一个有意思的问题,如果传入的Buffer不是direct buffer,那么先将数据读取到一个direct buffer,再全部拷贝到给定的buffer中,写其实也是这样的,这么做是为了填jvm实现的坑,参考知乎R大的回答:
Java NIO中,关于DirectBuffer,HeapBuffer的疑问?
FileDispatcherImpl.c的Java_sun_nio_ch_FileDispatcherImpl_read0关键源码:
1JNIEXPORT jint JNICALL
2Java_sun_nio_ch_FileDispatcherImpl_read0(JNIEnv *env, jclass clazz, jobject fdo,
3 jlong address, jint len) {
4 DWORD read = 0;
5 result = ReadFile(h, /* File handle to read */
6 (LPVOID)address, /* address to put data */
7 len, /* number of bytes to read */
8 &read, /* number of bytes read */
9 NULL); /* no overlapped struct */
10 return convertReturnVal(env, (jint)read, JNI_TRUE);
11}
虽然没有展开FileInputStream的源码,但是可以想到和写一样,其实都是对Windows API ReadFile的调用。
position
当前文件位置的读取和设置其实是通过一个方法完成的,FileChannelImpl.position0:
1private native long position0(FileDescriptor fd, long offset);
如果offset为-1,即表示读。实现位于FileChannelImpl.c中:
1JNIEXPORT jlong JNICALL
2Java_sun_nio_ch_FileChannelImpl_position0(JNIEnv *env, jobject this,
3 jobject fdo, jlong offset) {
4 DWORD lowPos = 0;
5 long highPos = 0;
6 HANDLE h = (HANDLE)(handleval(env, fdo));
7 if (offset < 0) {
8 lowPos = SetFilePointer(h, 0, &highPos, FILE_CURRENT);
9 } else {
10 lowPos = (DWORD)offset;
11 highPos = (long)(offset >> 32);
12 lowPos = SetFilePointer(h, lowPos, &highPos, FILE_BEGIN);
13 }
14 return (((jlong)highPos) << 32) | lowPos;
15}
SetFilePointer便是Windows API。
使用position时注意两点:
- 如果将位置设置在文件结束符之后,然后试图从文件通道中读取数据,读方法将返回-1 —— 文件结束标志。
- 如果将位置设置在文件结束符之后,然后向通道中写数据,文件将撑大到当前位置并写入数据。这可能导致“文件空洞”,磁盘上物理文件中写入的数据间有空隙。
文件裁剪/truncate
方法声明:
1public abstract FileChannel truncate(long size) throws IOException;
此方法的效果是size后面的部分都会被删除,同时position也会被设置到新的位置。
native实现位于FileDispatcherImpl.c:
1JNIEXPORT jint JNICALL
2Java_sun_nio_ch_FileDispatcherImpl_truncate0(JNIEnv *env, jobject this,
3 jobject fdo, jlong size) {
4 lowPos = SetFilePointer(h, lowPos, &highPos, FILE_BEGIN);
5 result = SetEndOfFile(h);
6 return 0;
7}
API SetEndOfFile的意思 是将当前位置(position)设为文件的末尾,这样就可以理解了。
强制刷新
方法声明:
1public abstract void force(boolean metaData) throws IOException;
此方法会导致被操作系统缓存在内存中的数据强制刷新到磁盘,参数metaData表示是否需要同时将元信息(比如权限信息)刷新至磁盘。
底层实现其实是对Windows API FlushFileBuffers的调用。
transferTo/transferFrom
这就是所谓的零拷贝技术,主要运用在从磁盘读取数据并通过网络进行发送这一场景,可将内存拷贝次数从4次(含两次内核空间和用户空间的相互拷贝)减少到2次。参考:
我们以transferTo为例进行说明,FileChannelImpl.transferTo的实现很有意思:
1public long transferTo(long position, long count,WritableByteChannel target) {
2 // Attempt a direct transfer, if the kernel supports it
3 if ((n = transferToDirectly(position, icount, target)) >= 0)
4 return n;
5 // Attempt a mapped transfer, but only to trusted channel types
6 if ((n = transferToTrustedChannel(position, icount, target)) >= 0)
7 return n;
8 // Slow path for untrusted targets
9 return transferToArbitraryChannel(position, icount, target);
10}
可以看出,将首先尝试进行零拷贝,一旦出错了(即返回错误的值)就表示内核不支持。transferToDirectly的native实现位于FileChannelImpl的transferTo0函数,Windows版的实现十分简单粗暴:
1JNIEXPORT jlong JNICALL
2Java_sun_nio_ch_FileChannelImpl_transferTo0(JNIEnv *env, jobject this,
3 jint srcFD,
4 jlong position, jlong count,
5 jint dstFD)
6{
7 return IOS_UNSUPPORTED;
8}
就是不支持。来看看隔壁Linux的实现:
1JNIEXPORT jlong JNICALL
2Java_sun_nio_ch_FileChannelImpl_transferTo0(JNIEnv *env, jobject this,
3 jint srcFD,
4 jlong position, jlong count,
5 jint dstFD){
6#if defined(__linux__)
7 off64_t offset = (off64_t)position;
8 jlong n = sendfile64(dstFD, srcFD, &offset, (size_t)count);
9 if (n < 0) {
10 if (errno == EAGAIN)
11 return IOS_UNAVAILABLE;
12 if ((errno == EINVAL) && ((ssize_t)count >= 0))
13 return IOS_UNSUPPORTED_CASE;
14 if (errno == EINTR) {
15 return IOS_INTERRUPTED;
16 }
17 JNU_ThrowIOExceptionWithLastError(env, "Transfer failed");
18 return IOS_THROWN;
19 }
20 return n;
21#elif
22//忽略solaris, mac等版本
23}
sendfile64便是linux的底层实现了。
从transferTo源码可以看出,如果内核不支持零拷贝,Java将尝试利用map实现,map是个什么东西,参加下面。
如果map也不支持,transferToArbitraryChannel所做的便是最low的方式: 先把数据从一个通道拷贝出来,再写到另一个通道,说的就是你,Windows。
内存映射
方法声明:
1public abstract MappedByteBuffer map(MapMode mode, long position, long size);
能够将一个文件映射到内存中,从而加快数据的读取速度,注意,如果只需要对一个文件进行少数据量(KB级)的读写,那么直接读写的性能其实更好,内存映射只有在数据量大、多次读写的情况下才能表现出来。MapMode共有三种取值:
- READ_ONLY,只读
- READ_WRITE,读写,任何写操作的结果都会被同步到磁盘
- PRIVATE,可读写,类似于copy on write,一个线程进行写操作会导致创建一个副本,而其它线程看不到当前线程的修改
Java中共有三个类可以获取到FileChannel,分别是FileOutputStream, FileInputStream和RandomAccessFile,考虑到它们分别是可写的,可读的和可读写的,所以每各类获得的通道分别可以使用哪些MapMode有一定的限制,总结如下:
| 类名 | FileOutputStream | FileInputStream | RandomAccessFile |
|---|---|---|---|
| MapMode | 无 | READ_ONLY | 全部 |
map的Java实现位于FileChannelImpl中,下面分部分进行说明.
规则检查
此部分对应上表的map规则,相应源码:
1if ((mode != MapMode.READ_ONLY) && !writable)
2 throw new NonWritableChannelException();
3if (!readable)
4 throw new NonReadableChannelException();
大小检查
1long filesize;
2do {
3 filesize = nd.size(fd);
4} while ((filesize == IOStatus.INTERRUPTED) && isOpen());
5if (!isOpen())
6 return null;
7//如果需要的大小大于实际的文件大小,那么对文件进行虚扩大
8if (filesize < position + size) { // Extend file size
9 if (!writable) {
10 throw new IOException("Channel not open for writing " +
11 "- cannot extend file to required size");
12 }
13 int rv;
14 do {
15 rv = nd.truncate(fd, position + size);
16 } while ((rv == IOStatus.INTERRUPTED) && isOpen());
17 if (!isOpen())
18 return null;
19}
20//需要的大小为0,返回一个逗你玩的buffer
21if (size == 0) {
22 addr = 0;
23 // a valid file descriptor is not required
24 FileDescriptor dummy = new FileDescriptor();
25 if ((!writable) || (imode == MAP_RO))
26 return Util.newMappedByteBufferR(0, 0, dummy, null);
27 else
28 return Util.newMappedByteBuffer(0, 0, dummy, null);
29}
映射
1int pagePosition = (int)(position % allocationGranularity);
2long mapPosition = position - pagePosition;
3long mapSize = size + pagePosition;
4addr = map0(imode, mapPosition, mapSize);
5FileDescriptor mfd = nd.duplicateForMapping(fd);
6int isize = (int)size;
7Unmapper um = new Unmapper(addr, mapSize, isize, mfd);
8if ((!writable) || (imode == MAP_RO)) {
9 return Util.newMappedByteBufferR(isize,
10 addr + pagePosition,
11 mfd,
12 um);
13} else {
14 return Util.newMappedByteBuffer(isize,
15 addr + pagePosition,
16 mfd,
17 um);
18}
map0的linux实现由系统调用mmap完成,返回映射文件的内存地址。duplicateForMapping用于复制句柄,在Windows上需要这么做,但在linux上不需要。
Util.newMappedByteBuffer(R)方法实际上是构造了一个direct buffer,buffer的起始地址便是mmap返回的内存地址。
文件锁
我们以方法:
1public abstract FileLock lock(long position, long size, boolean shared);
为例,参数position和size的作用是lock方法允许我们针对文件的某一部分进行锁定,shared参数用以控制获取的是共享锁还是排它锁,默认锁定(即无参数lock方法)全部文件、排它锁。
文件锁是针对进程(即一个JVM虚拟机)而言的,所以如果当前JVM已拥有文件的锁,而此JVM的另一个线程又尝试获取锁(同一个文件,有重复的区域),那么会抛出OverlappingFileLockException(共享锁、排它锁都会抛出),这是符合逻辑的,因为同一个JVM内的多个线程之间安全性应该由程序自己维护,而不是文件锁。
以上提到的特性很容易利用以下代码进行验证,假设有线程如下:
1private static class GETLock implements Runnable {
2 private final FileChannel channel;
3 private final int start;
4 private final int end;
5 private GETLock(FileChannel channel, int start, int end) {
6 this.channel = channel;
7 this.start = start;
8 this.end = end;
9 }
10 @Override
11 public void run() {
12 FileLock lock = channel.lock(start, end, true);
13 System.out.println(Thread.currentThread().getName() + "获得锁");
14 Thread.sleep(2000);
15 lock.release();
16 }
17}
验证代码:
1File file = new File("test");
2FileChannel channel = new RandomAccessFile(file, "rw").getChannel();
3new Thread(new GETLock(channel, 0, 2)).start();
4new Thread(new GETLock(channel, 1, 3)).start();
只要文件区域出现重复,便会抛出异常。
FileLock位于nio包,类图:
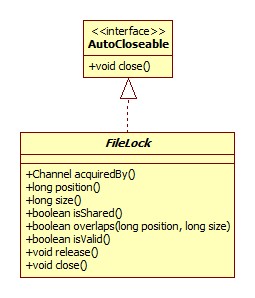
Java层面的实现位于FileChannelImpl.lock,下面对其进行分部分说明。
逻辑验证
1if (shared && !readable)
2 throw new NonReadableChannelException();
3if (!shared && !writable)
4 throw new NonWritableChannelException();
很容易理解,共享锁即读锁,如果获取到的通道不能读那么共享锁也就没有意义了 ,每种通道分别可以获得何种锁整理如下表:
| 类名 | FileInputStream | FileOutputStream | RandomAccessFile |
|---|---|---|---|
| 可获得的锁 | 共享锁 | 排它锁 | 全部 |
FileLockTable
如上文所述,文件锁的作用域为整个虚拟机,也就是说,两个channel如果对同一个文件的重复区域进行加锁,势必会导致OverlappingFileLockException,那么Java是如何在整个虚拟机范围(全局)进行检查的呢?答案便是FileLockTable。
其位于sun.nio.ch下,类图:
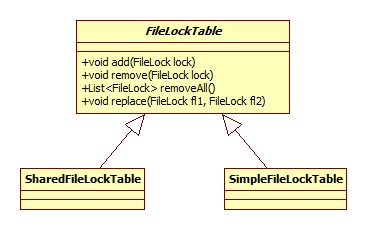
相关源码:
1FileLockImpl fli = new FileLockImpl(this, position, size, shared);
2FileLockTable flt = fileLockTable();
3flt.add(fli);
fileLockTable方法决定采用FileLockTable的哪一个实现类:
1private FileLockTable fileLockTable() throws IOException {
2 if (fileLockTable == null) {
3 synchronized (this) {
4 if (fileLockTable == null) {
5 if (isSharedFileLockTable()) {
6 fileLockTable = FileLockTable.newSharedFileLockTable(this, fd);
7 } else {
8 fileLockTable = new SimpleFileLockTable();
9 }
10 }
11 }
12 }
13 return fileLockTable;
14}
这里使用了一个双重检查,当然fileLockTable是volatile的。核心在于isSharedFileLockTable方法:
1private static boolean isSharedFileLockTable() {
2 if (!propertyChecked) {
3 synchronized (FileChannelImpl.class) {
4 if (!propertyChecked) {
5 String value = AccessController.doPrivileged(
6 new GetPropertyAction(
7 "sun.nio.ch.disableSystemWideOverlappingFileLockCheck"));
8 isSharedFileLockTable = ((value == null) || value.equals("false"));
9 propertyChecked = true;
10 }
11 }
12 }
13 return isSharedFileLockTable;
14}
可以看出,这里其实是根据属性disableSystemWideOverlappingFileLockCheck来决定是否采用全局模式,当然value默认为null.
那么SharedFileLockTable又是如何保证的呢?玄机就在于其保存文件锁的载体:
1private static ConcurrentHashMap<FileKey, List<FileLockReference>> lockMap =
2 new ConcurrentHashMap<FileKey, List<FileLockReference>>();
静态。map的key为FileKey对象,由SharedFileLockTable的构造器创建:
1SharedFileLockTable(Channel channel, FileDescriptor fd) {
2 this.channel = channel;
3 this.fileKey = FileKey.create(fd);
4}
FileKey是平台相关的,我们来看一下Linux的实现,类图:

st_dev是所在设备的ID,st_ino是文件的inode号,静态方法create完成了native方法init的调用:
1JNIEXPORT void JNICALL
2Java_sun_nio_ch_FileKey_init(JNIEnv *env, jobject this, jobject fdo) {
3 struct stat64 fbuf;
4 int res;
5 RESTARTABLE(fstat64(fdval(env, fdo), &fbuf), res);
6 if (res < 0) {
7 JNU_ThrowIOExceptionWithLastError(env, "fstat64 failed");
8 } else {
9 //设置st_dev和st_ino
10 (*env)->SetLongField(env, this, key_st_dev, (jlong)fbuf.st_dev);
11 (*env)->SetLongField(env, this, key_st_ino, (jlong)fbuf.st_ino);
12 }
13}
fstat64就是fstat函数,为Linux下的系统调用,用以获得文件的相关信息。
map的value中FileLockReference为对FileLock的弱引用。
到这里SharedFileLockTable的add方法的逻辑就很容易想到了: 如果map中不存在此文件的记录,添加之,如果存在,检查是否有区域重复。
重复性检查由SharedFileLockTable的checkList完成,源码:
1private void checkList(List<FileLockReference> list, long position, long size) {
2 for (FileLockReference ref: list) {
3 FileLock fl = ref.get();
4 if (fl != null && fl.overlaps(position, size))
5 throw new OverlappingFileLockException();
6 }
7}
FileLock.overlaps:
1public final boolean overlaps(long position, long size) {
2 if (position + size <= this.position)
3 return false; // That is below this
4 if (this.position + this.size <= position)
5 return false; // This is below that
6 return true;
7}
一目了然。
加锁
native方法Java_sun_nio_ch_FileDispatcherImpl_lock0完成,linux实现由函数fcntl完成,可以参考:
size
用以获取文件的大小,Linux实现和FileKey的init方法一样,由fstat完成,注意File的length方法的Linux实现由stat完成。而stat和fstat的主要区别是后者的第一个参数为文件描述符(只有打开了文件才会有),而前者的第一个参数是绝对的路径,不要求打开文件,这就和Java里两者的区别很好的印证。
关闭
FileChannel继承自AbstractInterruptibleChannel,通道关闭有此类实现,包括Socket通道也是如此:
1public final void close() {
2 synchronized (closeLock) {
3 if (!open)
4 return;
5 open = false;
6 implCloseChannel();
7 }
8}
implCloseChannel方法由FileChannelImpl实现:
1protected void implCloseChannel() throws IOException {
2 // Release and invalidate any locks that we still hold
3 if (fileLockTable != null) {
4 for (FileLock fl: fileLockTable.removeAll()) {
5 synchronized (fl) {
6 if (fl.isValid()) {
7 nd.release(fd, fl.position(), fl.size());
8 ((FileLockImpl)fl).invalidate();
9 }
10 }
11 }
12 }
13 threads.signalAndWait();
14 if (parent != null) {
15 ((java.io.Closeable)parent).close();
16 } else {
17 nd.close(fd);
18 }
19}
分为如下几步:
-
线程唤醒, 在Linux上如果有线程阻塞在一个文件描述符上,那么即使此文件描述符(FD)被关闭,被阻塞的线程也不会被唤醒,
1threads.signalAndWait();正是用于将这些线程手动唤醒,threads是一个NativeThreadSet类型,在任何IO操作(比如write方法)前被加入,这一点可以在第一节"写"中得到验证。
-
清除文件锁表
-
调用依赖的资源的close方法。
关于唤醒线程安全这一点,其实有一个隐含的线程安全的问题,结合read方法源码:
1public int read(ByteBuffer dst) throws IOException {
2 ensureOpen();
3 if (!readable)
4 throw new NonReadableChannelException();
5 synchronized (positionLock) {
6 int n = 0;
7 int ti = -1;
8 try {
9 begin();
10 ti = threads.add();
11 if (!isOpen())
12 return 0;
13 //here!
14 do {
15 n = IOUtil.read(fd, dst, -1, nd);
16 } while ((n == IOStatus.INTERRUPTED) && isOpen());
17 return IOStatus.normalize(n);
18 } finally {
19 threads.remove(ti);
20 end(n > 0);
21 assert IOStatus.check(n);
22 }
23 }
24}
如果进行通道关闭的线程唤醒被阻塞的线程、关闭文件描述符这一过程在读线程的最后一次isOpen检查和read调用之间完成(即上面源码中here处)完成,由于内核会对文件描述符进行回收(重用),这样完全会导致read操作读取的是一个全新的文件描述符!
JDK解决的办法在于NativeThreadSet.signalAndWait中(简略版):
1void signalAndWait() {
2 synchronized (this) {
3 while (used > 0) {
4 try {
5 wait();
6 } catch (InterruptedException e) {
7 interrupted = true;
8 }
9 }
10 }
11}
used表示正在进行读写的线程数,可以看出,只要尚有线程正在进行读写操作,关闭线程就会阻塞。那什么时候被唤醒呢?remove方法源码:
1void remove(int i) {
2 synchronized (this) {
3 elts[i] = 0;
4 used--;
5 if (used == 0 && waitingToEmpty)
6 notifyAll();
7 }
8}
这就保证了当进行实际的文件描述符关闭时,一定没有正在读写的线程,这就杜绝了上述情况的发生。